Deploy a machine learning application with Streamlit and Docker on AWS
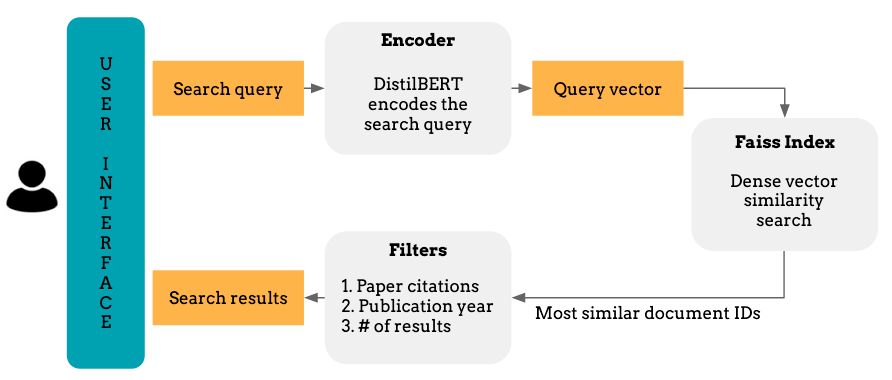
In the previous blog, we discussed how to build a semantic search engine with sentence transformers and Faiss. Here, we will create a Streamlit application and deploy the search engine both locally and on AWS Elastic Beanstalk.
If you want to jump straight into the code, check out the GitHub repo!
Streamlit application
Streamlit is an open-source Python library that makes it easy to create applications for machine learning and data science. With Streamlit, you don’t need to learn Flask or any frontend development and you can focus solely on your application.
Our app will help users search for academic articles. Users will type text queries in a search box and retrieve the most relevant publications and their metadata. They will also be able to choose the number of returned results and filter them by the number of paper citations and the publication year.
Behind the scenes, we will vectorise the search query with a sentence-DistilBERT model and pass it onto a pre-built Faiss index for similarity matching. Faiss will measure the L2 distance between the query vector and the indexed paper vectors and return a list of paper IDs that are closest to the query.
Let’s see how the app will look like and then dive into the code.
Prototyping a Streamlit application
Let’s import the required Python packages.
Next, we will write a few functions to load the data, transformer model and Faiss index. We will cache them with Streamlit’s @st.cache decorator to speed up our application.
Finally, we will create the main body of the application.
Let’s examine the code line by line:
- Lines 4–6: Call the functions shown above to load and cache the data and models.
- Line 8: Set the title of our application.
- Lines 14–17: Create the search engine filters and place them on a sidebar.
- Line 22: Do a semantic search for a given text query and return the paper IDs of the most relevant results. These will be ordered based on their similarity to the text query.
- Lines 24–28: Filter the data by publication year and the number of papers’ citations.
- Lines 30–34: For each paper ID retrieved in Line 22, fetch its metadata from the filtered dataset.
- Lines 36–43: Print the paper’s metadata, namely the title, citations, publication year and abstract.
Dockerizing the application
We will package the application with all of its dependencies in a container using Docker. We will create a Dockerfile which is a text document containing the commands (i.e. instructions) to assemble an image. If you are not familiar with Docker, this guide offers an in-depth introduction.
FROM python:3.8-slim-buster
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
EXPOSE 8501
ENTRYPOINT ["streamlit","run"]
CMD ["app.py"]
Let’s explain line by line what this Dockerfile will do:
- Line 1: Fetch a Python base image.
- Line 3: Change the working directory to /app
- Line 4: Pip install the requirements.txtfile.
- Line 5: Make the container listen on the 8501 port at runtime.
- Line 6: Execute the command streamlit runwhen starting the container.
- Line 7: Specify the arguments that will be fed to the ENTRYPOINT, in our case, the file name of our app.
Now, assuming that Docker is running on your machine, we can the image with the following command:
$ docker build -t <USERNAME>/<YOUR_IMAGE_NAME> .
The build command will create an image with the Dockerfile’s spec. Now, we are ready to deploy our application!
Deploying the application
Local deployment
Deploying our semantic search engine locally is straightforward. Having built the image, we will use the command to spin our application in a container. We will also add the -p argument to publish the container’s port at 8501.
$ docker run -p 8501:8501 <USERNAME>/<YOUR_IMAGE_NAME>
You can access the application at the following address:
http://localhost:8501/
AWS Elastic Beanstalk deployment
To deploy our application on AWS, we need to publish our image on a registry which can be accessed by the cloud provider. For convenience, let’s go with Docker Hub. If you haven’t pushed an image before, the client might ask you to login. Provide the same credentials that you used for logging into Docker Hub. Note that this step might take a while as our image is fairly large!
$ docker push <USERNAME>/<YOUR_IMAGE_NAME> .
Publishing your image on a public registry is not compulsory, however, it simplifies the deployment by skipping few configuration steps.
Now, we are almost ready to deploy our image on AWS Elastic Beanstalk (EB). Let’s list the steps:
- Login to AWS Console and search for Elastic Beanstalk.
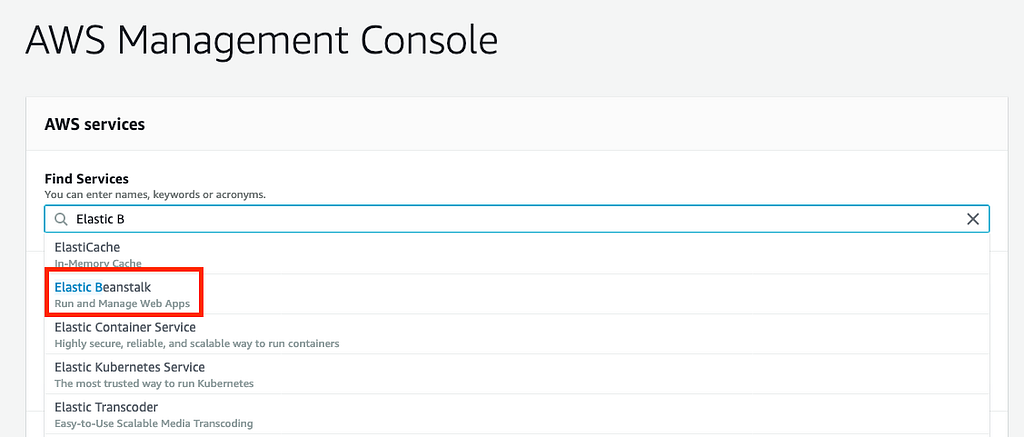
- Click on the Create Application button and name your application.
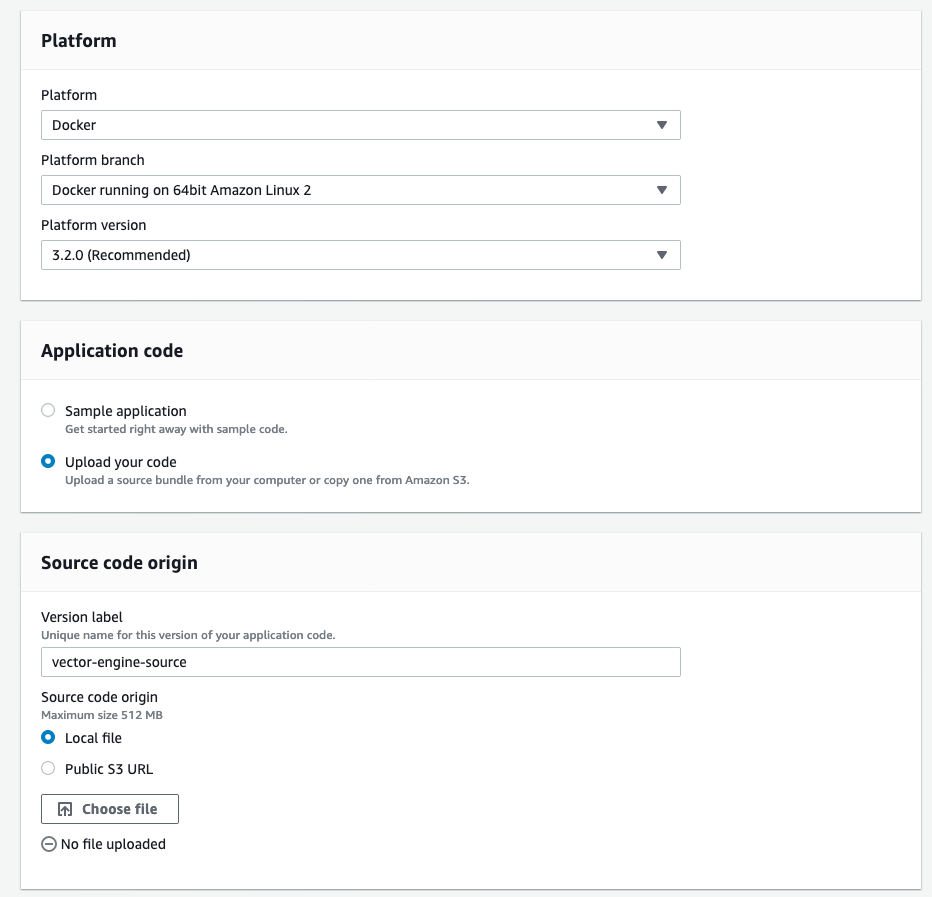
- Edit Instances and Capacity. Starting with Instances, change the Root volume type to General Purpose (SSD) and the Size to 8GB. Scroll to the bottom of the page and click on Save. Next, choose Capacity and change the Instance type from t2.micro to t3.medium. Note that the EC2 instance we selected is not in the free tier and you will be charged for using it. Make sure you shut down your application once you are done with it!

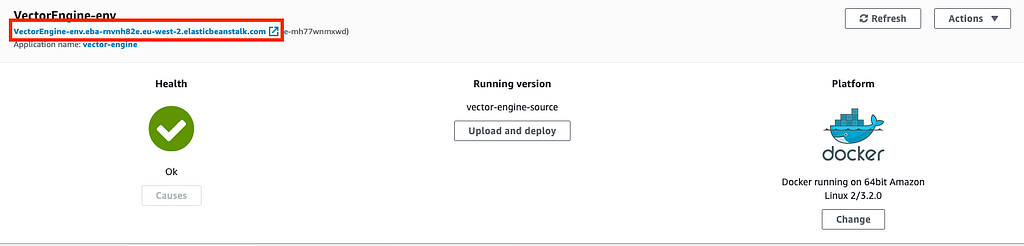
- Click on Create app. EB will take a few minutes to deploy our application. Once it’s done, you will be able to access and share the semantic search engine via its URL!
Conclusion
In this tutorial, I showed you how to prototype an application with Streamlit and deploy with Docker both locally and on AWS Elastic Beanstalk. Let me know in the comments if you have any questions.
The code is available on GitHub!
How to deploy a semantic search engine with Streamlit and Docker on AWS Elastic Beanstalk was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
