At the end of 2012 I launched a search engine that combined the offerings of six different second hand websites in Belgium. It was called ‘Zoekertjesland’ and indexed well over 3 million items.
Last week however I unplugged the server and stopped the project. I’m a student and renting a VPS for 2 years without any income from the website is costly.
In this post I’ll walk you through the technical aspects of building a meta-search engine like this one (with PHP, MariaDB and Sphinx).
Overall setup & goals
Before we dive into the technical aspects of building a meta-search engine, let’s take a look at the goals that I had for this project:
The setup that I came up with is pretty small, yet efficient enough to run on a relatively small VPS:
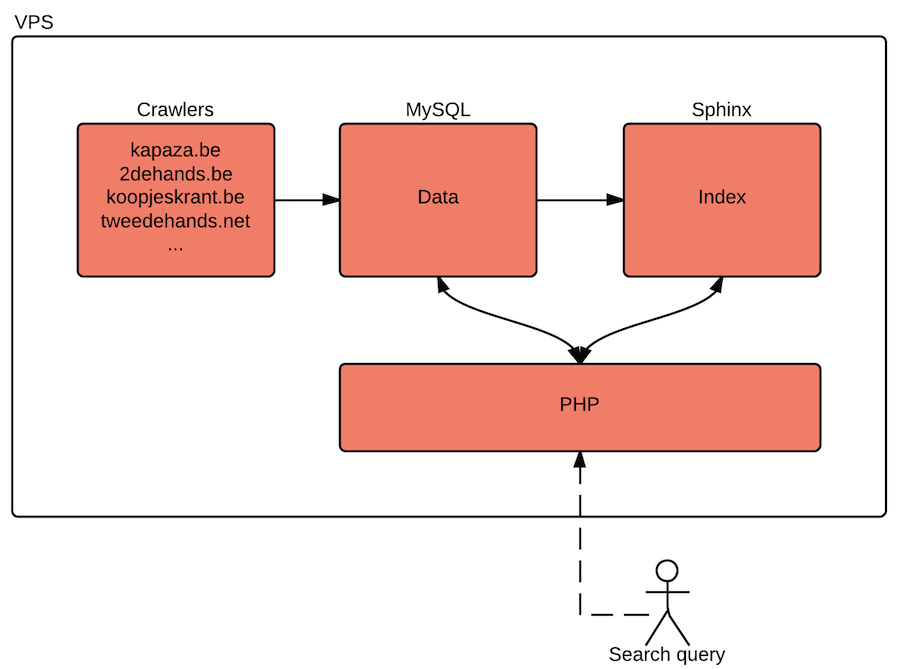
Crawlers
The crawlers are PHP scripts that are running continuously in the background, scraping data from several websites. I wrote one crawler for every website I wanted to index. The data that they gather (id, title, description, url, …) is stored in the MariaDB database. Each entry gets a last_updated attribute to keep track of how long it has been since it was last updated.
Choosing PHP for the crawlers might seem like a stupid idea. After all, it’s an interpreted language that isn’t really known for its speed. During the development I rewrote one of the crawlers in Java using jsoup. Performance of the Java version was a lot better than the PHP crawlers (up to 3 times faster) but the crawlers used far more memory. In fact, I wasn’t able to run multiple Java crawlers simultaneously on my VPS (maybe my Java skills are to blame?). So I decided to stick to the language I knew best (and felt most comfortable with) and to sacrifice some performance for it.
The PHP crawlers use cURL to fetch web pages and Simple HTML DOM Parser to extract the contents of them. I choose to use cURL because it allows you to control things like timeout and redirects (it’s also faster than file_get_contents).
Keeping the crawlers running
The crawlers are written to keep running, even in the case of errors. However, it sometimes happens that one of the scripts crashes. To keep the scripts running, I triggered each crawler every 5 minutes with a cronjob.
You might think, wait a minute! That means that after 10minutes you’d have two instances of the same script running. You would be correct! When I was testing the scripts I didn’t realise this and ended up with many instances of every crawler. To fix this, I used this piece of PHP code:
This code tries to lock the current PHP file. If it fails to lock the current file it knows that another instance is already running and dies. If this file wasn’t locked already, it gets locked and the crawler starts. If a running script suddenly stops, the lock is released and a new instance will be spawned by cron. It is simple but very effective! This way I was sure that each crawler would get restarted within 5 minutes if something went wrong. This is an example of a cronjob for a crawler:
The site originally used a MySQL back-end to store all the data of an item. I choose InnoDB as the storage engine because it uses row locking. This enables multiple crawlers to update data simultaneously, without having to wait on each other.
This is the data that was stored for each item:
After a few months of running the website, my hosting provider launched a new VPS platform. I decided to move since the new platform gave users more RAM for about the same price. While I was moving I switched from MySQL to MariaDB. There wasn’t a real benefit to it. I just wanted to work with something that was getting a lot of attention. The switch was painless as MariaDB is a drop-in replacement for MySQL!
After a few hours of running the crawlers, the database was populated with well over 3 million items. I figured this number might grow rapidly when I would write new crawlers for new websites. Searching through this database was painfully slow since InnoDB didn’t support full text search indexes at the time.
I quickly found a popular, open source search server: Sphinx. It fetches data from a source (in this case the MariaDB database) and creates an index that can be searched in milliseconds. It also has an amazing set of features and is small and efficient.
So went on installing Sphinx on the server and setting everything up. Sphinx indexes all the data that a source gives it. I configured it to index the id, title, description, price and location fields of each item. Indexing the price might seem odd but allows for queries like these: “Give me all items with a price between X and Y”. The same goes for the location: it’s nice to be able to only show items that are located close to you.
The last part of the configuration was to set up the index and search daemon. This is mostly the default configuration:
I won’t go into much detail here. Setting up Sphinx is really easy if you read the documentation. This post isn’t a guide on setting everything up. It’s just to show the architecture of a meta-search engine.
Keeping the index fresh
There is one problem though. What happens to second hand items that where sold and removed from the original websites? They are still stored in the database and even worse, they are being displayed to users as results!
At first I thought about writing a script that visits the URL of each item and verify that it is still alive. But this would be a time and bandwidth consuming activity with 3 million items!
The solution was much simpler though. The crawlers took between 1 and 2 days to completely re-crawl all six indexed websites. Removed articles won’t be re-crawled and thus won’t be updated. This means that these items will carry a last_updated data thats older than 2 days.
To keep the database clean, all I had to do was write a script that removes all items that haven’t been updated in the last 2 days. This script runs everyday and keeps the index fresh. It’s a very simple and efficient solution. Broken links where rarely encountered by users.
The front-end
Every search engine needs a front-end and the one I built was pretty simple. The homepage featured a Google-like design with just a search box and submit button.
The results page was simple as well. It was generated by PHP and featured some filtering and sorting options:
So far I’ve talked about the front and back-end. Let’s talk about the bridge between the two!
Journey of a query
A lot happens behind the scenes when a user sends a query to the search engine. Let me explain how the independent systems work together to show up results. This is the sequence diagram for a query on Zoekertjesland:
When PHP receives the search query, it creates a new instance of the SphinxClient and connects to the Sphinx instance on the server. Filters and sorting modes are also set. Users can filter & sort on price and location.
When the request is made, Sphinx looks up all the matching items in its index. But Sphinx only returns ID’s of items. It doesn’t return the title, url or other useful information of these results. So with those ID’s in hand, PHP turns to the database for additional information. It makes a query to MariaDB and fetches all the additional information that we want to show on the results page. Now PHP composes a nice page and gives it back to the user.
This proces is actually quite fast. Result pages where rendered within 0.1 to 0.2 seconds. Keep in mind that all these services where running on a VPS with moderate specs, not on dedicated hardware.
Looking back
Zoekertjesland has been an amazing project for me. I launched it when I was 18 years old. The idea was simple but I quickly stumbled upon a few problems that required some creative problem solving skills. I’m glad that I was able to make everything work.
Over the course of 2 years, Zoekertjesland welcomed over 21,500 unique visitors. They came to find great second hand deals and stayed on the website for more than 5 minutes. In its lifetime, the search engine processed 40,105 unique search queries.
